Service Discovery
Microservice Architecture 에서 서비스 찾기
모놀리식 아키텍처에서는 단일 서비스에서 모든것을 해결하기 때문에 서비스의 개념은 객체 인스턴스를 의미하고, 서비스를 이용한다 혹은 서비스를 호출한다는 의미는 해당 객체 인스턴스에서 메소드를 호출하는 것을 이야기한다.
반면 마이크로 서비스 아키텍처의 특징중에 하나는 많은 서비스 들이 각자 독립적인 컴포넌트 혹은 컨테이너로 존재하며, 각 서비스는 다른 서비스를 호출하고, 다른 서비스에 의해서 호출 당하는 관계를 가진다는 것이다.
모놀리식에서는 어떠한 객체 인스턴스를 찾아서 어떠한 메소드를 호출하느냐의 문제가 있고, 이 부분은 의외로 쉽다.
마이크로 서비스 아키텍처는 특정 서비스의 엔드포인트를 찾아서 REST Call 이나 RPC 를 통한 통신을 수행한다.
그렇다면 어떤 방식으로 서비스를 호출할 수 있는지 알아보자.
서비스 이용하기의 기본
이미 알다시피 서비스 컴포넌트는 자신만의 서비스 엔드포인트를 가지고 있다. 가장 기본적으로 IP/Port 를 이용한 방법이다. 일반적으로 IP 는 특정 서비스가 실행되고 있는 노드를 의미하며, Port 는 해당 노드에 수행되고 있는 어플리케이션(서비스)를 의미한다.
OnPreme 시스템 중에서 단순한 시스템은 서비스와 통신하기 위해서 고정 IP/Port 를 이용하여 해당 어플리케이션에 접근하고, 특정한 경로 URI 를 활용하여 서비스를 호출하게 된다.
이런 방식은 이미 과거가 되어버린 접근 방법이라고 할 수 있다. 최근 컨테이너 기반의 어플리케이션이 주를 이루면서 고정된 IP와 Port 는 더이상 사용할 수 없는 상태가 되었다.
고정 IP/Port 의 장점
- 고정 IP/Port 를 통해 쉬운 접근과 서비스에 대한 이해를 가진다.
- 서비스의 모든 상태와 로그는 해당 노드에 접근하면 쉽게 취할 수 있다.
고정 IP/Port 의 단점
- 서비스가 증가되면 혹은 HA를 구성해야하는 경우 새로운 도구 / 장비를 도입해야한다. (L4)
- 인프라와, 어플리케이션 개발 운영사이에 커플링이 발생한다. (인프라가 L4에 바인딩을 해 주어야 서비스를 이중화 할 수 있다.)
- 시스템의 스케일이 매우 어렵다. (단순하게 인스턴스를 늘여가고 싶겠지만 인프라와의 커플링은 이러한 작업을 매우 어렵게 만든다.)
- L4 자체가 단일 실패 지점이다.
위와 같은 장단점이 있지만, 특별한 대안이 따로 존재하지 않았었고, 그래도 이중화는 안정적인 서비스를 위해 필수적인 내용이었기 때문에 위 구조를 주로 채택하였다.
달라진 요구사항
과거와는 달리 이제는 컨테이너 어플리케이션 시대가 되었다.
컨테이너는 서비스가 특정 노드를 차지 아는것이 아니라. 언제든지 연관된 클러스터내의 특정 노드에서 서비스가 실행될 수 있는 구조를 가진다. 이 의미는 더이상 서비스를 고정된 IP/Port 를 통해서 접근할 수 없다는 의미이며, 해당 서비스는 특정 물리적 노드에 종속적인 상태값과 커플링이 되지 않는 구조로 설계 된다는 의미이다.
- 컨테이너는 동적으로 IP가 변경이 될 수 있다.
- 서비스는 여러개의 서비스 인스턴스로 수평 확장이 이루어지며, 이는 운영자가 임의로 조정하기 보다 자동으로 이루어진다. 이를 보통 AutoScaling 이라고 한다.
- REST Api, RPC 등과 같은 다양한 통신 프로토콜을 활용할 수 있어야한다.
- 서비스를 등록하고 검색할 수 있는 기능이 필요하며, 서비스 이름과 같은 특정 키를 활용하여 서비스에 접근할 수 있어야한다.
- 서비스는 스스로 서비스 엔드포인트를 공개하고, 자신을 등록해야한다.
위와 같은 요구사항이 생기면서 서비스 디스커버리가 필수가 되었다.
Service Registry
컨테이너 기반의 서비스가 활성화 되면서 서비스는 우선 서비스를 등록하고, 서비스를 찾을 수 있도록 저장 공간을 필요로 하게 된다.
서비스 디스커버리는 이러한 일을 처리하는 주체이며 서비스들을 등록관리하고, 서비스의 목록을 필요한 클라이언트로 응답하는 역할을 한다.
from : https://www.nginx.com/wp-content/uploads/2016/04/Richardson-microservices-part4-1_difficult-service-discovery.png
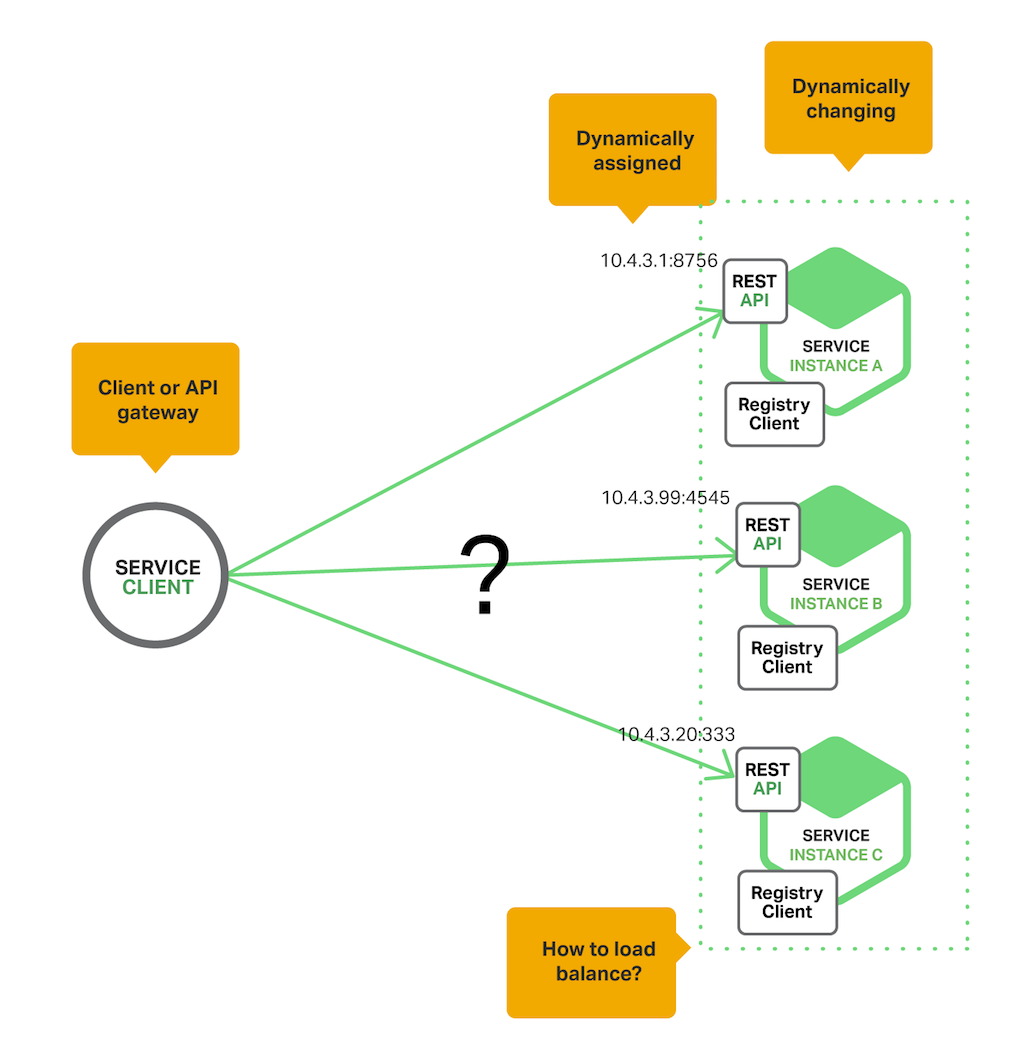
서비스 요구사항
- 서비스 인스턴스는 원격 API 를 드러내어야한다. 이는 HTTP / Thrift / rpc 등이 있을 수 있다.
- 서비스 인스턴스 수와 인스턴스의 노드는 동적으로 변경될 수 있다.
- 서비스 레지스터리는 서비스의 위치를 저장하는 데이터베이스 역할을 한다.
- 서비스 인스턴스는 서비스 레지스터리에 등록이 되며, 서비스의 시작과 종료시에 등록이 되거나 해제된다.
- 서비스의 클라이언트는 서비스 레지스터리에 요청을 하여 필요한 서비스를 찾아간다.
이중 서비스의 위치를 저장하는 역할을 하는 것이 서비스 레지스터리이다.
서비스 레지스터리는 컴포넌트 기반의 서비스에서는 필수 요건이라고 할 수 있다.
Client Side Service Discovery
서비스를 사용하는 측은 서비스의 위치를 알아야한다. IP 주소를 이용하건, 도메인 이름을 이용하건 서비스를 찾아야 해당 서비스와 통신을 할 수 있다.
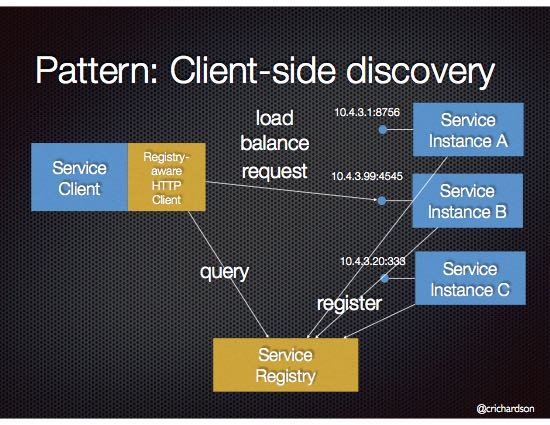
조금전에 Service Registry 를 알아보았다. 그럼 클라이언트 사이드 서비스 디스커버리는 클라이언트 자체적으로 서비스를 찾아내는 기능을 탑재하는 형태라고 할 수 있다.
서비스 디스커버리는 자신이 요청할 대상 서비슬 찾고, 해당 서비스가 서비스가 가능하면, 서비스의 엔드포인트로 연결하여 서비스를 요청하는 구조이다.
from : https://microservices.io/i/servicediscovery/client-side-discovery.jpg
동작 과정
- 특정 작업을 위해서 서비스 호출 모듈을 이용하여 특정 서비스 엔드포인트를 호출한다.
- 클라이언트 서비스 디스커버리는 로컬 캐시에서 서비스를 조회하고, 없는경우 서비스 레지스터리에서 대상 서비스를 조회한다.
- 대상 서비스 목록을 가져와서 로컬 캐시에 담는다.
- 대상 서비스로 비즈니스 요청을 보내고 응답을 받는다. 이때 특정 알고리즘을 이용하여 대상 서비스에 골고루 분산되도록 한다. (예_ 라운드로빈)
- 캐싱 타임이 지나면 대상 서비스 목록을 서비스 레지스터리에서 조회하여 대상을 캐싱한다.
- 캐싱시에는 대상 서비스가 정상으로 동작하는지 확인한다.
장점
- 클라이언트가 직접 서비스 정보를 가지고 있으므로, 로컬 캐싱을 이용하게 되며, 이는 빠른 응답속도를 낼 수 있다.
- 서비스 특화된 디스커버리를 운영할 수 있다.
- 클라이언트에서 직접 서비스로 연동이 되므로 홉이 줄어든다.
단점
- 서비스 디스커버리를 서비스 자체적으로 수행해야하기 때문에, 개발, 운영 오버헤드가 발생한다.
- 클라이언트의 본질적인 비즈니스 로직 이외의 기능 로직이므로, 비즈니스와 상관이 없는 코드를 관리해야한다.
- 서비스 특화된 운영으로 서비스 디스커버리를 확장하는 경우 버져닝 이슈가 존재할 수 있다.
- 서비스 레지스터리와 강하게 커플링 되어 있다.
Servier Side Service Discovery
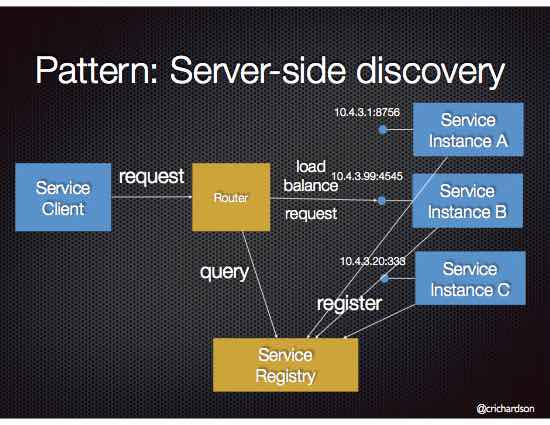
서버사이드 서비스 디스커버리의 경우에는 서비스를 발견하고, 서비스 엔드포인트 관리를 수행하는 컴포넌트가 상주하는 형태이다.
서버사이드 서비스 디스커버리는 서비스 레지스터리에 접근하여 등록된 서비스의 목록을 관리하고, 서비스의 시작, 수행중, 오류, 종료 등과 같은 상태에 따라 서비스 목록을 동적으로 수정한다.
서버사이드 서비스 디스커버리는 구조에 따라서는 LoadBalancer로 라우팅 역할도 수행한다.
from: https://microservices.io/i/servicediscovery/server-side-discovery.jpg
동작과정
- 서버사이드 서비스 디스커버리는 서비스 목록을 갱신하기 위해서 주기적으로 서비스 레지스터리에 접근한다.
- 서비스 목록을 가져와서 helath 체크를 수행하고, 정상/비정상에 따라서 서비스 목록을 갱신한다.
- 서비스 디스커버리 역할만 수행한다면 클라이언트 요청시 최신 서비스 목록 정보를 클라이언트로 내려준다.
- 라우팅 역할을 같이 수행하는 서비스 디스커버리 인경우, 요청을 대상 엔드포인트로 전달한다.
장점
- 클라이언트 코드는 단일 엔드포인트로 요청을 보낼 수 있어 코드가 간단하다. (단일 엔드포인트는 서비스 디스커버리가 된다.)
- 비교적 헬스체크 실패가 난 서비스에 접속에 대해서 덜 민감하다.
단점
- 별도의 서비스 디스커버리 전용 컴포넌트가 설치 운영 되어야한다.
- 서비스 디스커버리 자체가 단일 실패지점(SPOF)이기 때문에 HA 가 반드시 구성되어야한다.
- 네트워크 홉이 추가로 발생된다.
- 라우팅을 지원하기 위한 프로토콜 구현체를 서비스 디스커버리가 가지고 있어야한다. (REST API, RPC, Thrift등 여러 요구를 수용할수록 더욱 복잡하고, 장애요인도 늘어난다.)
관련 툴
서비스 디스커버리만 수행
- Eureka 가 대표적인 서비스 디스커버리이며, 이는 서비스를 등록하고, health status 관리만 수행한다.

from : https://miro.medium.com/max/1400/1*ITGONeSNR8GBm-UznTNODA.png
서비스 디스커버리 + 라우팅 (로드밸런서)
- Marathon LB (MESOS 기반의 클러스터 오케스트레이션에서 주로 사용)

from : https://docs.d2iq.com/mesosphere/dcos/services/img/marathon-edge-external-facing.png
- Kubernetes: Kubernetes 자체 DNS 서비스를 이용하여 라우팅 한다.

from : https://d33wubrfki0l68.cloudfront.net/bf8e5eaac697bac89c5b36a0edb8855c860bfb45/6944f/images/docs/nodelocaldns.svg
결론
지금까지 서비스 디스커버리에 대해 알아 보았다. 서비스 디스커버리는 처음 나열한 요구사항을 수용하기 위해서 마이크로 서비스 아키텍처에서는 필수적인 요소이다.
서비스 디스커비리를 위해서 우선은 서비스를 등록하고, 이를 저장할 수 있는 데이터베이스 역할을 하는 서비스 레지스터리를 알아 보았고, 서비스 디스커버리 역할을 누가 수행하는지에 따라서 서버사이드 서비스 디스커버리와, 클라이언트 사이드 서비스 디스커버리도 살펴 보았다. 그리고 서비스 디스커버리의 역할중에서 단순 서비스 목록을 전달하는 역할과, 리퀘스트를 라우팅 하는 역할에 대해서도 잠깐이나마 살펴 보았다.
서비스 디스커버리는 MSA 에서 핵심적인 코어 부분이며, 왜 이것이 필요한지에 대한 근본 이해를 한다면 쉽게 접근할 수 있을 것이다.
참고
- https://microservices.io/patterns/client-side-discovery.html
- https://microservices.io/i/servicediscovery/server-side-discovery.jpg
- https://kubernetes.io/ko/docs/tasks/administer-cluster/coredns/
- https://medium.com/swlh/spring-cloud-service-discovery-with-eureka-16f32068e5c7